Regression and classification¶
Tutorial 1: Basic regression¶
In this tutorial, we show how to train a regularized least-squares (RLS) regressor. We use the classical computational short-cuts [1] for fast regularization and leave-one-out cross-validation.
Data set¶
We consider the classical Boston Housing data set from the UCI machine learning repository. The data consists of 506 instances, 13 features and 1 output to be predicted.
The data can be loaded from disk and split into a training set of 250, and test set of 256 instances using the following code.
import numpy as np
def load_housing():
np.random.seed(1)
D = np.loadtxt("housing.data")
np.random.shuffle(D)
X = D[:,:-1]
Y = D[:,-1]
X_train = X[:250]
Y_train = Y[:250]
X_test = X[250:]
Y_test = Y[250:]
return X_train, Y_train, X_test, Y_test
def print_stats():
X_train, Y_train, X_test, Y_test = load_housing()
print("Housing data set characteristics")
print("Training set: %d instances, %d features" %X_train.shape)
print("Test set: %d instances, %d features" %X_test.shape)
if __name__ == "__main__":
print_stats()
Housing data set characteristics
Training set: 250 instances, 13 features
Test set: 256 instances, 13 features
Linear regression with default parameters¶
In this example we train RLS with default parameters (linear kernel, regparam=1.0) and compute the mean squared error both for leave-one-out cross-validation, and for the test set.
In order to check that the resulting model is better than a trivial baseline, we compare the results to a predictor, that always predicts the mean of training outputs.
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Trains RLS with default parameters (regparam=1.0, kernel='LinearKernel')
X_train, Y_train, X_test, Y_test = load_housing()
learner = RLS(X_train, Y_train)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
#Test set predictions
P_test = learner.predict(X_test)
print("leave-one-out error %f" %sqerror(Y_train, P_loo))
print("test error %f" %sqerror(Y_test, P_test))
#Sanity check, can we do better than predicting mean of training labels?
print("mean predictor %f" %sqerror(Y_test, np.ones(Y_test.shape)*np.mean(Y_train)))
if __name__=="__main__":
train_rls()
The resulting output is as follows.
leave-one-out error 25.959399
test error 25.497222
mean predictor 81.458770
Clearly the model works much better than the trivial baseline. Still, since we used default parameters there is no guarantee that the regularization parameter would be close to optimal value.
Choosing regularization parameter with leave-one-out¶
Next, we choose the regularization parameter based on grid search in an exponential grid. We select the parameter that leads to lowest leave-one-out cross-validation error (measured with mean square error). Due to the computational short-cuts implemented the whole procedure is almost as fast as training RLS once (though on this small data set the running times would yet not be an issue even for brute force algorithms that require re-training for each tested parameter and round of cross-validation).
from rlscore.learner import RLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Select regparam with leave-one-out cross-validation
X_train, Y_train, X_test, Y_test = load_housing()
learner = RLS(X_train, Y_train)
best_regparam = None
best_error = float("inf")
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
e = sqerror(Y_train, P_loo)
print("regparam 2**%d, loo-error %f" %(log_regparam, e))
if e < best_error:
best_error = e
best_regparam = regparam
learner.solve(best_regparam)
P_test = learner.predict(X_test)
print("best regparam %f with loo-error %f" %(best_regparam, best_error))
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
regparam 2**-15, loo-error 24.745479
regparam 2**-14, loo-error 24.745463
regparam 2**-13, loo-error 24.745431
regparam 2**-12, loo-error 24.745369
regparam 2**-11, loo-error 24.745246
regparam 2**-10, loo-error 24.745010
regparam 2**-9, loo-error 24.744576
regparam 2**-8, loo-error 24.743856
regparam 2**-7, loo-error 24.742982
regparam 2**-6, loo-error 24.743309
regparam 2**-5, loo-error 24.750966
regparam 2**-4, loo-error 24.786243
regparam 2**-3, loo-error 24.896991
regparam 2**-2, loo-error 25.146493
regparam 2**-1, loo-error 25.537315
regparam 2**0, loo-error 25.959399
regparam 2**1, loo-error 26.285436
regparam 2**2, loo-error 26.479254
regparam 2**3, loo-error 26.603001
regparam 2**4, loo-error 26.801196
regparam 2**5, loo-error 27.352322
regparam 2**6, loo-error 28.837002
regparam 2**7, loo-error 32.113350
regparam 2**8, loo-error 37.480625
regparam 2**9, loo-error 43.843555
regparam 2**10, loo-error 49.748687
regparam 2**11, loo-error 54.912297
regparam 2**12, loo-error 59.936226
regparam 2**13, loo-error 65.137825
regparam 2**14, loo-error 70.126118
regparam 2**15, loo-error 74.336978
best regparam 0.007812 with loo-error 24.742982
test error 24.509981
Compared to previous case, we were able to slightly lower the error, though it turns out in this case the default parameter was already close to optimal. Usually one cannot expect to be so lucky.
For convenience, the procedure of training RLS and simultaneously selecting the regularization parameter with leave-one-out is implemented in class LeaveOneOutRLS.
from rlscore.learner import LeaveOneOutRLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Trains RLS with automatically selected regularization parameter
X_train, Y_train, X_test, Y_test = load_housing()
regparams = [2.**i for i in range(-15, 16)]
learner = LeaveOneOutRLS(X_train, Y_train, regparams = regparams)
loo_errors = learner.cv_performances
P_test = learner.predict(X_test)
print("leave-one-out errors " +str(loo_errors))
print("chosen regparam %f" %learner.regparam)
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
leave-one-out errors [ 24.74547881 24.74546295 24.74543138 24.74536884 24.74524616
24.74501033 24.7445764 24.74385625 24.74298177 24.74330936
24.75096639 24.78624255 24.89699067 25.14649266 25.53731465
25.95939943 26.28543584 26.47925431 26.6030015 26.80119588
27.35232186 28.83700156 32.11334986 37.48062503 43.84355496
49.7486873 54.91229746 59.93622566 65.1378248 70.12611801
74.33697809]
chosen regparam 0.007812
test error 24.509981
Learning nonlinear predictors using kernels¶
Next we train RLS using a non-linear kernel function. The Gaussian kernel has a single parameter, the kernel width gamma, that needs to be selected using cross-validation. We implement a nested loop, where gamma is selected in the outer loop, and regparam in the inner. The ordering is important, as it allows us to make use of the fast algorithm for re-training RLS with different regularization parameter values.
from rlscore.learner import RLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Selects both the gamma parameter for Gaussian kernel, and regparam with loocv
X_train, Y_train, X_test, Y_test = load_housing()
regparams = [2.**i for i in range(-15, 16)]
gammas = regparams
best_regparam = None
best_gamma = None
best_error = float("inf")
for gamma in gammas:
#New RLS is initialized for each kernel parameter
learner = RLS(X_train, Y_train, kernel="GaussianKernel", gamma=gamma)
for regparam in regparams:
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
e = sqerror(Y_train, P_loo)
#print "regparam", regparam, "gamma", gamma, "loo-error", e
if e < best_error:
best_error = e
best_regparam = regparam
best_gamma = gamma
learner = RLS(X_train, Y_train, regparam = best_regparam, kernel="GaussianKernel", gamma=best_gamma)
P_test = learner.predict(X_test)
print("best parameters gamma %f regparam %f" %(best_gamma, best_regparam))
print("best leave-one-out error %f" %best_error)
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
best parameters gamma 0.000031 regparam 0.000244
best leave-one-out error 21.910837
test error 16.340877
Clearly there is a non-linear relationship between the features and the output, that the Gaussian kernel allows us to model better than the linear kernel. For simpler implementation, the inner loop could be replaced with training LeaveOneOutRLS supplying the grid as a parameter, the results and running time are the same.
import numpy as np
from rlscore.learner import LeaveOneOutRLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Selects both the gamma parameter for Gaussian kernel, and regparam with loocv
X_train, Y_train, X_test, Y_test = load_housing()
regparams = [2.**i for i in range(-15, 16)]
gammas = regparams
best_regparam = None
best_gamma = None
best_error = float("inf")
best_learner = None
for gamma in gammas:
#New RLS is initialized for each kernel parameter
learner = LeaveOneOutRLS(X_train, Y_train, kernel="GaussianKernel", gamma=gamma, regparams=regparams)
e = np.min(learner.cv_performances)
if e < best_error:
best_error = e
best_regparam = learner.regparam
best_gamma = gamma
best_learner = learner
P_test = best_learner.predict(X_test)
print("best parameters gamma %f regparam %f" %(best_gamma, best_regparam))
print("best leave-one-out error %f" %best_error)
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
best parameters gamma 0.000031 regparam 0.000244
best leave-one-out error 21.910837
test error 16.340877
Using a custom kernel¶
Custom kernel functions are supported via the kernel=”PrecomputedKernel” -option, which allows the user to directly give a precomputed kernel matrix for training (and later for prediction). Revisiting the first example, we again train a regressor on the Housing data:
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import sqerror
from housing_data import load_housing
def train_rls():
#Trains RLS with a precomputed kernel matrix
X_train, Y_train, X_test, Y_test = load_housing()
#Minor techincal detail: adding 1.0 simulates the effect of adding a
#constant valued bias feature, as is done by 'LinearKernel' by deafault
K_train = np.dot(X_train, X_train.T) + 1.0
K_test = np.dot(X_test, X_train.T) + 1.0
learner = RLS(K_train, Y_train, kernel="PrecomputedKernel")
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
#Test set predictions
P_test = learner.predict(K_test)
print("leave-one-out error %f" %sqerror(Y_train, P_loo))
print("test error %f" %sqerror(Y_test, P_test))
#Sanity check, can we do better than predicting mean of training labels?
print("mean predictor %f" %sqerror(Y_test, np.ones(Y_test.shape)*np.mean(Y_train)))
if __name__=="__main__":
train_rls()
leave-one-out error 25.959399
test error 25.497222
mean predictor 81.458770
Tutorial 2: K-fold cross-validation, non i.i.d. data¶
Next we consider how to implement K-fold cross-validation. RLS implements computational shortcuts for repeated holdout, that allow implementing different cross-validation schemes with almost the same computational cost as training RLS only once. This can be used to implement regular 10-fold or 5-fold cross-validation if one prefers these to leave-one-out, though in our opinion the main advantage is realized with non i.i.d. data, where leave-one-out cannot be used reliably. The computational shortcuts are based on further refinement of the results published in [2] and [3], the parse ranking experiments presented next are similar to the experimental setup considered in [2].
We consider an application from the field of natural language processing known as parse ranking. Syntactic parsing refers to the process of analyzing natural language text according to some formal grammar. Due to ambiguity of natural language (“I shot an elephant in my pyjamas.” - just who was in the pyjamas?), a sentence can have multiple grammatically correct parses. In parse ranking, an automated parser generates a set of candidate parsers, which need to be scored according to how well they match the true (human made) parse of the sentence.
This can be modeled as a regression problem, where the data consists of inputs representing sentence-parse pairs, and outputs that are scores describing the ‘goodness’ of the parse for the sentence. The learned predictor should generalize to making predictions for new sentences. In order to represent this requirement in the experimental setup, the training and test data split is done on the level of sentences, so that all parses related to same sentence are put either in the training or test set.
Thus a main feature of the data is that it is not an i.i.d. sample, rather the data is sampled in groups of parses, each group corresponding to one sentence. Similar violation of the i.i.d. assumption is common in many other machine learning applications. Typical situations where this type of cross-validation may be required include setting where several instances correspond to same real-world object (e.g. same experiment performed many times, same person at different time points), pairwise data (customer-product, drug-target, query-document, parse-sentence), data corresponding to points in some coordinate system (pixels in image, spatial data, time series data) etc.
The data set¶
The parse ranking data set can be downloaded from here.
First, we load the training set in and examine its properties
import numpy as np
from rlscore.utilities.reader import read_sparse
from rlscore.utilities.cross_validation import map_ids
def print_stats():
X_train = read_sparse("train_2000_x.txt")
Y_train = np.loadtxt("train_2000_y.txt")
ids = np.loadtxt("train_2000_qids.txt", dtype=int)
folds = map_ids(ids)
print("Parse data set characteristics")
print("Training set: %d instances, %d features" %X_train.shape)
print("Instances grouped into %d sentences" %len(folds))
if __name__=="__main__":
print_stats()
Parse data set characteristics
Training set: 2000 instances, 195100 features
Instances grouped into 117 sentences
As is common in natural language applications the data is very high dimensional. In addition to the data we load a list of sentence ids, denoting to which sentence each instance is associated with. Finally, with the map_ids function, based on the ids we map the data to fold indices, where each fold contains the indices of all training instances associated with a given sentence. Altogether there are 117 folds each corresponding to a sentence.
Incorrect analysis using leave-one-out¶
As before, we select the regularization parameter using leave-one-out.
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import sqerror
from rlscore.utilities.reader import read_sparse
def train_rls():
#Select regparam with leave-one-out cross-validation
X_train = read_sparse("train_2000_x.txt")
Y_train = np.loadtxt("train_2000_y.txt")
X_test = read_sparse("test_2000_x.txt", X_train.shape[1])
Y_test = np.loadtxt("test_2000_y.txt")
learner = RLS(X_train, Y_train)
best_regparam = None
best_error = float("inf")
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
e = sqerror(Y_train, P_loo)
print("regparam 2**%d, loo-error %f" %(log_regparam, e))
if e < best_error:
best_error = e
best_regparam = regparam
learner.solve(best_regparam)
P_test = learner.predict(X_test)
print("best regparam %d loo-error %f" %(best_regparam, best_error))
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
regparam 2**-15, loo-error 0.001104
regparam 2**-14, loo-error 0.001104
regparam 2**-13, loo-error 0.001103
regparam 2**-12, loo-error 0.001102
regparam 2**-11, loo-error 0.001101
regparam 2**-10, loo-error 0.001099
regparam 2**-9, loo-error 0.001096
regparam 2**-8, loo-error 0.001092
regparam 2**-7, loo-error 0.001086
regparam 2**-6, loo-error 0.001077
regparam 2**-5, loo-error 0.001064
regparam 2**-4, loo-error 0.001048
regparam 2**-3, loo-error 0.001027
regparam 2**-2, loo-error 0.001004
regparam 2**-1, loo-error 0.000986
regparam 2**0, loo-error 0.000978
regparam 2**1, loo-error 0.000993
regparam 2**2, loo-error 0.001043
regparam 2**3, loo-error 0.001150
regparam 2**4, loo-error 0.001345
regparam 2**5, loo-error 0.001668
regparam 2**6, loo-error 0.002175
regparam 2**7, loo-error 0.002943
regparam 2**8, loo-error 0.004113
regparam 2**9, loo-error 0.005966
regparam 2**10, loo-error 0.009000
regparam 2**11, loo-error 0.013866
regparam 2**12, loo-error 0.021092
regparam 2**13, loo-error 0.030709
regparam 2**14, loo-error 0.042223
regparam 2**15, loo-error 0.055301
best regparam 1 loo-error 0.000978
test error 0.044046
It can be seen that something has gone wrong, the test error is almost 50 times higher than the leave-one-out error! The problem is that in leave-one-out when a parse is left out of the training set, all the other parses related to the same sentence are still left in. This leads to high optimistic bias in leave-one-out.
K-fold cross-validation to the rescue¶
This time, we perform k-fold cross-validation, where each fold contains instances related to a single sentence (k=117).
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import sqerror
from rlscore.utilities.cross_validation import map_ids
from rlscore.utilities.reader import read_sparse
def train_rls():
#Select regparam with k-fold cross-validation,
#where instances related to a single sentence form
#together a fold
X_train = read_sparse("train_2000_x.txt")
Y_train = np.loadtxt("train_2000_y.txt")
X_test = read_sparse("test_2000_x.txt", X_train.shape[1])
Y_test = np.loadtxt("test_2000_y.txt")
#list of sentence ids
ids = np.loadtxt("train_2000_qids.txt")
#mapped to a list of lists, where each list
#contains indices for one fold
folds = map_ids(ids)
learner = RLS(X_train, Y_train)
best_regparam = None
best_error = float("inf")
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#K-fold cross-validation
P = np.zeros(Y_train.shape)
for fold in folds:
#computes holdout predictions, where instances
#in fold are left out of training set
P[fold] = learner.holdout(fold)
e = sqerror(Y_train, P)
print("regparam 2**%d, k-fold error %f" %(log_regparam, e))
if e < best_error:
best_error = e
best_regparam = regparam
learner.solve(best_regparam)
P_test = learner.predict(X_test)
print("best regparam %f k-fold error %f" %(best_regparam, best_error))
print("test error %f" %sqerror(Y_test, P_test))
if __name__=="__main__":
train_rls()
regparam 2**-15, k-fold error 0.043429
regparam 2**-14, k-fold error 0.043416
regparam 2**-13, k-fold error 0.043396
regparam 2**-12, k-fold error 0.043372
regparam 2**-11, k-fold error 0.043348
regparam 2**-10, k-fold error 0.043327
regparam 2**-9, k-fold error 0.043308
regparam 2**-8, k-fold error 0.043288
regparam 2**-7, k-fold error 0.043260
regparam 2**-6, k-fold error 0.043216
regparam 2**-5, k-fold error 0.043148
regparam 2**-4, k-fold error 0.043057
regparam 2**-3, k-fold error 0.042955
regparam 2**-2, k-fold error 0.042862
regparam 2**-1, k-fold error 0.042797
regparam 2**0, k-fold error 0.042768
regparam 2**1, k-fold error 0.042763
regparam 2**2, k-fold error 0.042758
regparam 2**3, k-fold error 0.042720
regparam 2**4, k-fold error 0.042625
regparam 2**5, k-fold error 0.042471
regparam 2**6, k-fold error 0.042289
regparam 2**7, k-fold error 0.042156
regparam 2**8, k-fold error 0.042207
regparam 2**9, k-fold error 0.042622
regparam 2**10, k-fold error 0.043615
regparam 2**11, k-fold error 0.045399
regparam 2**12, k-fold error 0.048230
regparam 2**13, k-fold error 0.052443
regparam 2**14, k-fold error 0.058417
regparam 2**15, k-fold error 0.066758
best regparam 128.000000 k-fold error 0.042156
test error 0.045575
This time everything works out better than before, the cross-validation estimate and test error are much closer. Interestingly, the regularization parameter chosen based on the more reliable estimate does not work any better than the one chosen with leave-one-out.
K-fold vs. leave-one-out¶
Finally, we plot the difference between the leave-sentence-out k-fold, leave-one-out and test set errors.
import numpy as np
import matplotlib.pyplot as plt
from rlscore.learner import RLS
from rlscore.measure import sqerror
from rlscore.utilities.cross_validation import map_ids
from rlscore.utilities.reader import read_sparse
def plot_rls():
#Select regparam with k-fold cross-validation,
#where instances related to a single sentence form
#together a fold
X_train = read_sparse("train_2000_x.txt")
Y_train = np.loadtxt("train_2000_y.txt")
X_test = read_sparse("test_2000_x.txt", X_train.shape[1])
Y_test = np.loadtxt("test_2000_y.txt")
#list of sentence ids
ids = np.loadtxt("train_2000_qids.txt")
#mapped to a list of lists, where each list
#contains indices for one fold
folds = map_ids(ids)
learner = RLS(X_train, Y_train)
best_regparam = None
best_error = float("inf")
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
kfold_errors = []
loo_errors = []
test_errors = []
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#K-fold cross-validation
perfs = []
for fold in folds:
#computes holdout predictions, where instances
#in fold are left out of training set
P = learner.holdout(fold)
perfs.append(sqerror(Y_train[fold], P))
e_kfold = np.mean(perfs)
kfold_errors.append(e_kfold)
P_loo = learner.leave_one_out()
e_loo = sqerror(Y_train, P_loo)
loo_errors.append(e_loo)
P_test = learner.predict(X_test)
e_test = sqerror(Y_test, P_test)
test_errors.append(e_test)
plt.semilogy(log_regparams, loo_errors, label = "leave-one-out")
plt.semilogy(log_regparams, kfold_errors, label = "leave-sentence-out")
plt.semilogy(log_regparams, test_errors, label = "test error")
plt.xlabel("$log_2(\lambda)$")
plt.ylabel("mean squared error")
plt.legend(loc=3)
plt.show()
if __name__=="__main__":
plot_rls()
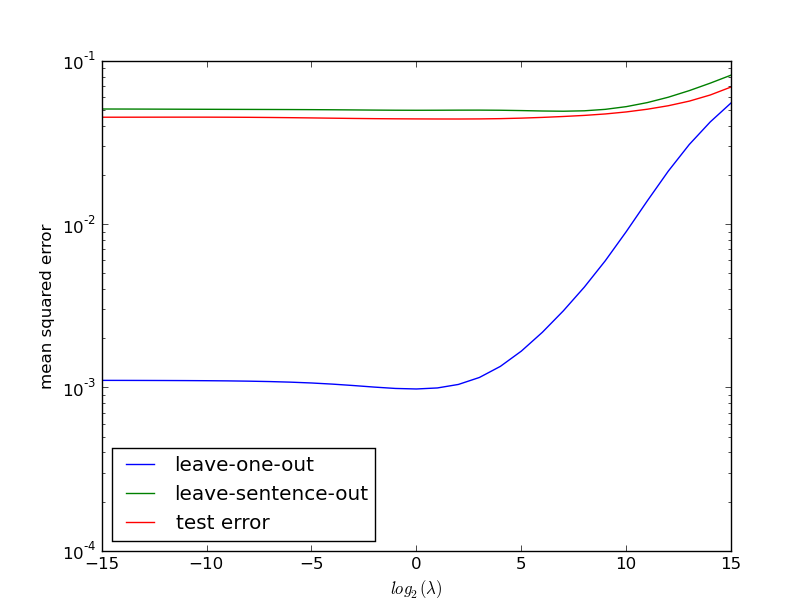
The moral of the story is, that if your data is not identically distributed, but rather sampled in groups, this should be taken into account when designing training/test split and/or the cross-validation folds. Cross-validation using such custom fold-partition can be implemented efficiently using the hold-out method implemented in the RLS module.
Note: One issue with this data set is that even though there is signal present in the data, even the best results are quite bad in terms of MSE. We cannot really accurately predict the scores as such.
Tutorial 3: Binary classification and Area under ROC curve¶
Adult data set¶
In this experiment, we build a binary classifier on the Adult data set. We model this as a regression problem, where +1 encodes the positive class, and -1 the negative one. This is the standard encoding assumed by the performance measures within the RLScore package.
from rlscore.utilities.reader import read_svmlight
def print_stats():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a")
print("Adult data set characteristics")
print("Training set: %d instances, %d features" %X_train.shape)
print("Test set: %d instances, %d features" %X_test.shape)
if __name__=="__main__":
print_stats()
Adult data set characteristics
Training set: 30956 instances, 123 features
Test set: 1605 instances, 119 features
Binary classification¶
We can train RLS and select the regularization parameter as before, by simply using (binary) classification accuracy instead of squared error as the performance measure.
from rlscore.learner import RLS
from rlscore.measure import accuracy
from rlscore.utilities.reader import read_svmlight
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a", X_train.shape[1])
learner = RLS(X_train, Y_train)
best_regparam = None
best_accuracy = 0.
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
acc = accuracy(Y_train, P_loo)
print("regparam 2**%d, loo-accuracy %f" %(log_regparam, acc))
if acc > best_accuracy:
best_accuracy = acc
best_regparam = regparam
learner.solve(best_regparam)
P_test = learner.predict(X_test)
print("best regparam %f with loo-accuracy %f" %(best_regparam, best_accuracy))
print("test set accuracy %f" %accuracy(Y_test, P_test))
if __name__=="__main__":
train_rls()
regparam 2**-15, loo-accuracy 0.844586
regparam 2**-14, loo-accuracy 0.844586
regparam 2**-13, loo-accuracy 0.844586
regparam 2**-12, loo-accuracy 0.844586
regparam 2**-11, loo-accuracy 0.844586
regparam 2**-10, loo-accuracy 0.844586
regparam 2**-9, loo-accuracy 0.844586
regparam 2**-8, loo-accuracy 0.844586
regparam 2**-7, loo-accuracy 0.844586
regparam 2**-6, loo-accuracy 0.844586
regparam 2**-5, loo-accuracy 0.844586
regparam 2**-4, loo-accuracy 0.844586
regparam 2**-3, loo-accuracy 0.844586
regparam 2**-2, loo-accuracy 0.844586
regparam 2**-1, loo-accuracy 0.844586
regparam 2**0, loo-accuracy 0.844618
regparam 2**1, loo-accuracy 0.844586
regparam 2**2, loo-accuracy 0.844650
regparam 2**3, loo-accuracy 0.844812
regparam 2**4, loo-accuracy 0.844780
regparam 2**5, loo-accuracy 0.844457
regparam 2**6, loo-accuracy 0.844392
regparam 2**7, loo-accuracy 0.843907
regparam 2**8, loo-accuracy 0.843455
regparam 2**9, loo-accuracy 0.843423
regparam 2**10, loo-accuracy 0.841679
regparam 2**11, loo-accuracy 0.839030
regparam 2**12, loo-accuracy 0.834119
regparam 2**13, loo-accuracy 0.822005
regparam 2**14, loo-accuracy 0.797002
regparam 2**15, loo-accuracy 0.771321
best regparam 8.000000 with loo-accuracy 0.844812
test set accuracy 0.837383
Area under ROC curve (AUC) and cross-validation¶
A common approach in machine learning is to measure performance with area under the ROC curve (AUC) rather than classification accuracy. Here, we combine the leave-one-out shortcuts, with using AUC for parameter selection and performance estimation.
from rlscore.learner import RLS
from rlscore.measure import auc
from rlscore.utilities.reader import read_svmlight
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a", X_train.shape[1])
learner = RLS(X_train, Y_train)
best_regparam = None
best_auc = 0.
#exponential grid of possible regparam values
log_regparams = range(-15, 16)
for log_regparam in log_regparams:
regparam = 2.**log_regparam
#RLS is re-trained with the new regparam, this
#is very fast due to computational short-cut
learner.solve(regparam)
#Leave-one-out cross-validation predictions, this is fast due to
#computational short-cut
P_loo = learner.leave_one_out()
acc = auc(Y_train, P_loo)
print("regparam 2**%d, loo-auc %f" %(log_regparam, acc))
if acc > best_auc:
best_auc = acc
best_regparam = regparam
learner.solve(best_regparam)
P_test = learner.predict(X_test)
print("best regparam %f with loo-auc %f" %(best_regparam, best_auc))
print("test set auc %f" %auc(Y_test, P_test))
if __name__=="__main__":
train_rls()
regparam 2**-15, loo-auc 0.896731
regparam 2**-14, loo-auc 0.896731
regparam 2**-13, loo-auc 0.896731
regparam 2**-12, loo-auc 0.896731
regparam 2**-11, loo-auc 0.896731
regparam 2**-10, loo-auc 0.896731
regparam 2**-9, loo-auc 0.896731
regparam 2**-8, loo-auc 0.896731
regparam 2**-7, loo-auc 0.896731
regparam 2**-6, loo-auc 0.896731
regparam 2**-5, loo-auc 0.896732
regparam 2**-4, loo-auc 0.896732
regparam 2**-3, loo-auc 0.896733
regparam 2**-2, loo-auc 0.896736
regparam 2**-1, loo-auc 0.896740
regparam 2**0, loo-auc 0.896750
regparam 2**1, loo-auc 0.896768
regparam 2**2, loo-auc 0.896796
regparam 2**3, loo-auc 0.896841
regparam 2**4, loo-auc 0.896893
regparam 2**5, loo-auc 0.896944
regparam 2**6, loo-auc 0.896978
regparam 2**7, loo-auc 0.896956
regparam 2**8, loo-auc 0.896825
regparam 2**9, loo-auc 0.896467
regparam 2**10, loo-auc 0.895527
regparam 2**11, loo-auc 0.893551
regparam 2**12, loo-auc 0.889980
regparam 2**13, loo-auc 0.884622
regparam 2**14, loo-auc 0.878469
regparam 2**15, loo-auc 0.871916
best regparam 64.000000 with loo-auc 0.896978
test set auc 0.893482
However, as shown for example in [4], especially for small data sets leave-one-out can have substantial bias for AUC-estimation. In this experiment, we split the Adult data set to 1000 separate training sets of 30 samples, and compare the leave-one-out AUC and test set AUC.
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import auc
from rlscore.utilities.reader import read_svmlight
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a", X_train.shape[1])
loo_aucs = []
test_aucs = []
for i in range(1000):
X_small = X_train[i*30: i*30 + 30]
Y_small = Y_train[i*30: i*30 + 30]
learner = RLS(X_small, Y_small)
P_loo = learner.leave_one_out()
loo_a = auc(Y_small, P_loo)
P_test = learner.predict(X_test)
test_a = auc(Y_test, P_test)
loo_aucs.append(loo_a)
test_aucs.append(test_a)
print("mean loo auc over 1000 repetitions %f" %np.mean(loo_aucs))
print("mean test auc over 1000 repetitions %f" %np.mean(test_aucs))
if __name__=="__main__":
train_rls()
mean loo auc over 1000 repetitions 0.709399
mean test auc over 1000 repetitions 0.734802
As can be seen, there is a systematic negative bias meaning that the leave-one-out AUCs tend to be smaller than the AUC on the (quite large) test set. The results are similar to those obtained in the simulated experiments in [4]. The bias can be removed by performing leave-pair-out cross-validation, where on each round of cross-validation one positive-negative example pair is left out of training set. For this purpose, RLScore implements the fast and exact leave-pair-out algorithm first introduced in [5]. What follows is a low-level implementation of leave-pair-out, where all such (x_i, x_j) pairs, where y_i = +1 and y_j = -1 are left out in turn. The leave-pair-out AUC is the relative fraction of such pairs, where the f(x_i) > f(x_j), with ties assumed to be broken randomly (see [4] for further discussion).
import numpy as np
from rlscore.learner import RLS
from rlscore.measure import auc
from rlscore.utilities.reader import read_svmlight
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a", X_train.shape[1])
lpo_aucs = []
test_aucs = []
for i in range(1000):
X_small = X_train[i*30: i*30 + 30]
Y_small = Y_train[i*30: i*30 + 30]
pairs_start = []
pairs_end = []
for i in range(len(Y_small)):
for j in range(len(Y_small)):
if Y_small[i] == 1. and Y_small[j] == -1.:
pairs_start.append(i)
pairs_end.append(j)
learner = RLS(X_small, Y_small)
pairs_start = np.array(pairs_start)
pairs_end = np.array(pairs_end)
P_start, P_end = learner.leave_pair_out(pairs_start, pairs_end)
lpo_a = np.mean(P_start > P_end + 0.5 * (P_start == P_end))
P_test = learner.predict(X_test)
test_a = auc(Y_test, P_test)
lpo_aucs.append(lpo_a)
test_aucs.append(test_a)
print("mean lpo over auc over 1000 repetitions: %f" %np.mean(lpo_aucs))
print("mean test auc over 1000 repetitions %f" %np.mean(test_aucs))
if __name__=="__main__":
train_rls()
mean lpo over auc over 1000 repetitions: 0.732587
mean test auc over 1000 repetitions 0.734802
As can be seen, the negative bias is now almost completely eliminated.
The above code is very low-level and as such unlikely to be easy to understand or of practical use for most users. However, leave-pair-out AUC can be automatically computed, and also used for model selection using the equivalent higher level interface. In the following experiment, we train RLS on a sample of 1000 instances from Adult data for regularization parameter values 2^-5, 1 and 2^5, and select the predictor corresponding to highest leave-pair-out AUC.
from rlscore.learner import LeavePairOutRLS
from rlscore.measure import auc
from rlscore.utilities.reader import read_svmlight
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
#subsample, leave-pair-out on whole data would take
#a lot of time
X_train = X_train[:1000]
Y_train = Y_train[:1000]
X_test, Y_test, foo = read_svmlight("a1a", X_train.shape[1])
regparams = [2.**-5, 1., 2.**5]
learner = LeavePairOutRLS(X_train, Y_train, regparams=regparams)
print("best regparam %f" %learner.regparam)
print("lpo auc " +str(learner.cv_performances))
P_test = learner.predict(X_test)
print("test auc %f" %auc(Y_test, P_test))
if __name__=="__main__":
train_rls()
best regparam 32.000000
lpo auc [ 0.88130354 0.88719854 0.8967489 ]
test auc 0.888468
Tutorial 4: Reduced set approximation¶
Once the data set size exceeds a couple of thousands of instances, maintaining the whole kernel matrix in memory is no longer feasible. Instead of using all the training data to represent the learned model, one can instead restrict the model to a subset of the data, resulting in the so-called reduced set approximation (aka ‘subset of regressors’, also closely related to Nyström approximation). As a starting point one can randomly select a couple of hundred of training instances as basis vectors. A lot of research has been done on more advanced selection strategies.
import numpy as np
from rlscore.learner import LeaveOneOutRLS
from rlscore.measure import accuracy
from rlscore.utilities.reader import read_svmlight
import random
random.seed(10)
def train_rls():
X_train, Y_train, foo = read_svmlight("a1a.t")
X_test, Y_test, foo = read_svmlight("a1a")
#select randomly 100 basis vectors
indices = range(X_train.shape[0])
indices = random.sample(indices, 100)
basis_vectors = X_train[indices]
regparams = [2.**i for i in range(-15, 16)]
gammas = [2**i for i in range(-10,1)]
best_regparam = None
best_gamma = None
best_acc = 0.
best_learner = None
for gamma in gammas:
#New RLS is initialized for each kernel parameter
learner = LeaveOneOutRLS(X_train, Y_train, basis_vectors= basis_vectors, kernel="GaussianKernel", gamma=gamma, regparams=regparams, measure=accuracy)
acc = np.max(learner.cv_performances)
print("gamma %f, regparam %f, accuracy %f" %(gamma, learner.regparam, acc))
if acc > best_acc:
best_acc = acc
best_regparam = learner.regparam
best_gamma = gamma
best_learner = learner
P_test = best_learner.predict(X_test)
print("best parameters gamma %f regparam %f" %(best_gamma, best_regparam))
print("best leave-one-out accuracy %f" %best_acc)
print("test set accuracy %f" %accuracy(Y_test, P_test))
if __name__=="__main__":
train_rls()
gamma 0.000977, regparam 0.062500, accuracy 0.844812
gamma 0.001953, regparam 0.250000, accuracy 0.844812
gamma 0.003906, regparam 0.500000, accuracy 0.844715
gamma 0.007812, regparam 0.015625, accuracy 0.844489
gamma 0.015625, regparam 0.500000, accuracy 0.844101
gamma 0.031250, regparam 0.250000, accuracy 0.844650
gamma 0.062500, regparam 0.000031, accuracy 0.843972
gamma 0.125000, regparam 0.062500, accuracy 0.841743
gamma 0.250000, regparam 0.000031, accuracy 0.834087
gamma 0.500000, regparam 0.000031, accuracy 0.821424
gamma 1.000000, regparam 0.031250, accuracy 0.819163
best parameters gamma 0.000977 regparam 0.062500
best leave-one-out accuracy 0.844812
test set accuracy 0.841745
Tutorial 5: Multi-target learning¶
RLS supports efficient multi-target learning. Instead of a single vector of outputs Y, one can supply [instances x targets] shape Y-matrix. For multi-target regression, one can simply insert the values to be regressed as such. For multi-class or multi-label classification, one should employ a transformation, where Y-matrix contains one column per class. The class(es) to which an instance belongs to are encoded as +1, while the others are encoded as -1 (so called one-vs-all transformation, in case of multi-class problems).
All the cross-validation and fast regularization algorithms are compatible with multi-target learning.
We demonstrate multi-class learning with a simple toy example, utilizing the Wine data set from the UCI repository
import numpy as np
def load_wine():
np.random.seed(1)
D = np.loadtxt("wine.data", delimiter=",")
np.random.shuffle(D)
X = D[:,1:]
Y = D[:,0].astype(int)
X_train = X[:100]
Y_train = Y[:100]
X_test = X[100:]
Y_test = Y[100:]
return X_train, Y_train, X_test, Y_test
def print_stats():
X_train, Y_train, X_test, Y_test = load_wine()
print("Wine data set characteristics")
print("Training set: %d instances, %d features" %X_train.shape)
print("Test set: %d instances, %d features" %X_test.shape)
if __name__=="__main__":
print_stats()
Wine data set characteristics
Training set: 100 instances, 13 features
Test set: 78 instances, 13 features
We implement the training and testing, using two additional helper functions, one which transforms class labels to one-vs-all encoding, another that computes classification accuracy for matrices using one-vs-all encoding.
from rlscore.learner import LeaveOneOutRLS
from rlscore.measure import ova_accuracy
from wine_data import load_wine
from rlscore.utilities.multiclass import to_one_vs_all
def train_rls():
X_train, Y_train, X_test, Y_test = load_wine()
#Map labels from set {1,2,3} to one-vs-all encoding
Y_train = to_one_vs_all(Y_train, False)
Y_test = to_one_vs_all(Y_test, False)
regparams = [2.**i for i in range(-15, 16)]
learner = LeaveOneOutRLS(X_train, Y_train, regparams=regparams, measure=ova_accuracy)
P_test = learner.predict(X_test)
#ova_accuracy computes one-vs-all classification accuracy directly between transformed
#class label matrix, and a matrix of predictions, where each column corresponds to a class
print("test set accuracy %f" %ova_accuracy(Y_test, P_test))
if __name__=="__main__":
train_rls()
test set accuracy 0.987179
The wine data turns out to be really easy to learn. Similarly, we could implement multi-target regression, or multi-label classification. RLScore does not currently implement a wide variety of multi-label classification measures. However, the implemented performance measures (e.g. accuracy, auc, f-score), will compute micro-averaged performance estimates (i.e. compute the measure for each column separately and then average), when applied to 2-dimensional Y and P matrices.
References¶
| [1] | Ryan Rifkin, Ross Lippert. Notes on Regularized Least Squares. Technical Report, MIT, 2007. |
| [2] | (1, 2) Tapio Pahikkala, Jorma Boberg, and Tapio Salakoski. Fast n-Fold Cross-Validation for Regularized Least-Squares. Proceedings of the Ninth Scandinavian Conference on Artificial Intelligence, 83-90, Otamedia Oy, 2006. |
| [3] | Tapio Pahikkala, Hanna Suominen, and Jorma Boberg. Efficient cross-validation for kernelized least-squares regression with sparse basis expansions. Machine Learning, 87(3):381–407, June 2012. |
| [4] | (1, 2, 3) Antti Airola, Tapio Pahikkala, Willem Waegeman, Bernard De Baets, and Tapio Salakoski An experimental comparison of cross-validation techniques for estimating the area under the ROC curve. Computational Statistics & Data Analysis, 55(4):1828-1844, April 2011. |
| [5] | Tapio Pahikkala, Antti Airola, Jorma Boberg, and Tapio Salakoski. Exact and efficient leave-pair-out cross-validation for ranking RLS. In Proceedings of the 2nd International and Interdisciplinary Conference on Adaptive Knowledge Representation and Reasoning (AKRR‘08), pages 1-8, Espoo, Finland, 2008. |